
")
KubeCon+CloudNativeCon Europe 2025の2日目のキーノートセッションから、Red Hatのエンジニアが生成AIのためのプラットフォームについて解説したセッションを紹介する。これはスポンサーによるキーノートとして行われたもので、約7分という短い時間ながらも、生成AIの特性、ベースとなるKubernetesのエコシステムで注目されるプロジェクトなどについて解説したものだ。Red Hatの視点からどのプロジェクトが生成AIのために必要だと考えているのかを考える上で参考になるだろう。
動画は以下のURLから参照できる。
●動画:The Weight of Data: Rethinking Cloud-Native Systems for the Age of AI
セッションは生成AIが利用するデータに注目して、日本語では「データの重み:AIの時代にクラウドネイティブなシステムについて再考する」という意味のタイトルが付けられており、生成AIが利用するデータ、そしてそれを扱うアプリケーションがこれまでのステートレスなアプリケーションとは違うというポイントから解説を行っている。元のタイトルは「The Weight of Data: Rethinking Cloud-Native Systems for the Age of AI」になる。登壇したのはAPACのCTO、Vincent Caldeira氏とシニアプリンシパルエンジニアのHolly Cummins氏だ。

登壇したCaldeira氏(左)とCummins氏(右)
まず生成AIを単体のLLMアプリとして開発した場合、そのモデルデータをData Gravity(データの持つ重力)と表現。ここではそのモデルデータが最も重要になることを示した。
そして複数のコンポーネントが連携して実行されるというマイクロサービス的なアプリケーションが現代のAIアプリケーションであると説明した。生成AIのアプリケーションはKubernetesでオーケストレーションされるアプリケーションと相似しているとして、複数の言語モデルを上位のオーケストレーターとエージェントが運用するという形式はKubernetesと外形的には同じだと説明。興味深いのはここでは単一の大規模言語モデルに依存したアプリケーションではなく、複数のモデルが連携するアーキテクチャーが新しい時代のAIシステムであると解説しているところだろう。
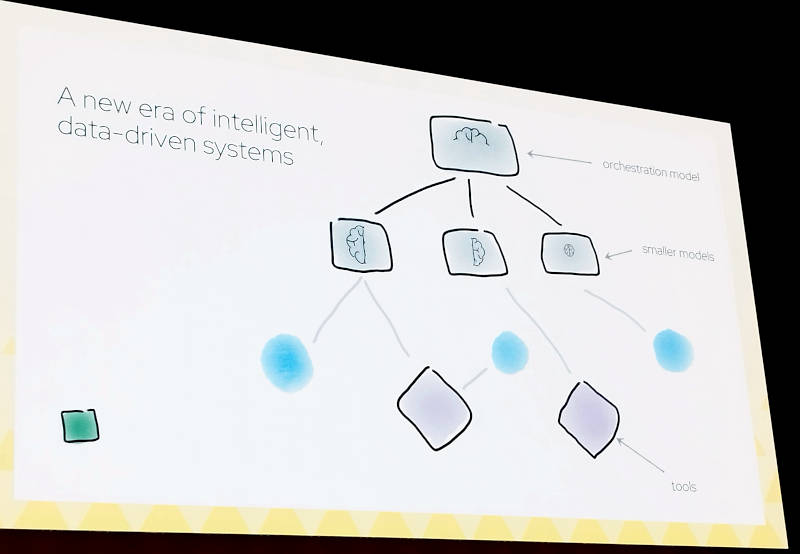
複数の生成AIのモデルをオーケストレーションする発想はKubernetesと同じ
しかしそこに大きな違いがあるとして説明したのは、アプリケーションのState(状態)という部分だ。クラウドネイティブなシステムはそもそもステートレスなコンポーネントが集まって構成されており、ステートレスであるがゆえにスケーラブルなシステムとなる。一方生成AIの場合、アプリケーションはステートフルであることが必要だと説明した。

Kubernetesをステートフルなシステムのために使うには何を変えればいいのか?
ここからはCaldeira氏がプレゼンテーションを引き継いだ。Kubernetesはステートフルなワークロードをサポートしているとして、Persistent VolumeやStatefulSets、Daemon Setsなどの機能を例に挙げた。そしてストレージについてはMySQL互換の分散データベースであるVitessや分散ストレージのRookが存在していることを説明。Vitessについては2023年にパリで開催されたKubeCon Europe 2023のセッションを紹介する記事を参照して欲しい。
●参考:KubeCon Europe 2023よりGitHubがMySQL互換のVitessを使った事例のセッションを紹介
そしてイベント駆動型のアプリケーションをKubernetesで実装するためのソフトウェアであるKnativeや、KafkaをKubernetesで実装したソフトウェアなどが存在することを説明。Red Hatが開発をリードしているKafka on KubernetesであるStrimziの名称が出てきていないのが不思議だ。KubeConの共催イベントである「Data on Kubernetes Day」で行われたRed HatのセッションではStrimziとそのリバランスのためのソフトウェア、Cruise Controlが紹介されている。そのセッションについては以下の記事を参照して欲しい。
●参考:KubeCon+CloudNativeCon Europe 2025開幕、Kafkaのリバランス問題を解決するセッションを紹介
Strimziについては2024年にオンラインイベントとして開催されたStrimziConで行われたセッションも参考になるだろう。
●参考:Kafka on Kubernetesを実現するStrimziに特化したカンファレンスStrimziCon 2024からキーノートを紹介
ただしAIのアプリケーションは単に状態を保持するだけではなく、データを変更したり他のアプリケーションと共有したりする機能が必要となると説明した。

ノードをまたがる形で状態を保持したうえでスケールする機能には多くの制限が存在する
そして生成AIに特化したステート管理とスケジューリングの機能が必要になると説明した。それを実現するためにハードウェアに近いテクノロジーとして共有メモリー型のマルチプロセッサシステム(NUMA)やGPUのノードトポロジーを意識したスケジューリング機能を例に挙げた。またLLMを接続するためのゲートウェイや障害が発生した際のリカバリーを可能にする機能など、大量のデータを利用しながらステートを保持し、フォルトトレーラントなシステムを構成する必要性を説明した。
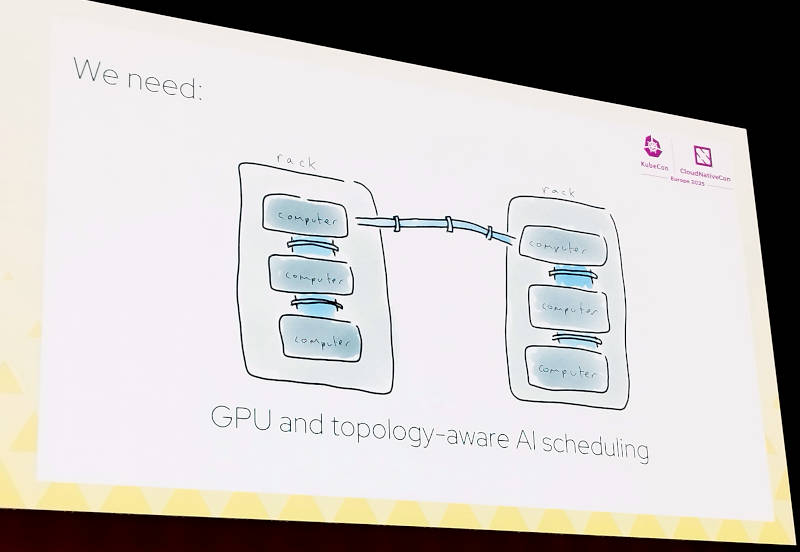
GPUのノードを意識したスケジューリング機能が必要
ここではそれらの必須な要件を列挙したうえで、CNCFがホストするプロジェクトでカバーできているエリアもあることを紹介。

必要要件をカバーするCNCFのプロジェクトを紹介
ここで例に挙げられているのはKueue、Envoy AI Gateway、KserveとvLLM、DaprそしてOpenTelemetryである。KueueはバッチジョブをKubernetesで実行するためにGoogleが開発して公開しているコントローラー、Envoy AI GatewayはEnvoyを使ったLLMへのルーティングなどを行うゲートウェイ、KserveはKubernetes上で機械学習を実行するためのコントロールプレーン、vLLMはUCバークレイで開発されオープンソースプロジェクトとなった推論のためのライブラリー、DaprはもともとMicrosoftが開発していた分散アプリケーション実行のためのランタイムで、現在はDiagridが開発を続けているソフトウェアだ。OpenTelemetryはオブザーバービリティの領域ではほぼデファクトスタンダードとなったツールの総称であり、SDKとAPI、コレクターなどから構成される。これら以外にもVolcanoやArmada、KubeRayなどもLLMの実装には多く採用されており、ここでは割愛されているのは限られた発表時間ゆえのRed Hatによる選択ということだろうか。
ここで解説されたクラウドネイティブなAIシステムについては、TAG-Runtimeの下部組織であるCloud Native Ai Working Groupで議論されていることを付け加えた。以下のリンクからその内容を参照できる。
●参考:Announcing the AI Working Group’s new Cloud Native Artificial Intelligence whitepaper
全体的な内容として、ステートレスなKubernetesからステートフルでデータヘビーな生成AIをどうやってこれから実装していくのか、それに使われるプロジェクトは何か、などをRed Hatの視点からまとめた内容となっている。短い時間の中で、多くの要素を詰め込まずにデータに対する重要性、ステートレスなシステムとの違いだけを解説していた。セキュリティやデータソブリンティなどの面倒な概念は避けて、あくまでもハードウェアの特性を活かしたアーキテクチャーやツールについて述べることで、TAG-RuntimeのAIワークグループに参加して欲しいと訴求したセッションとなった。これまでの堅いイメージのRed Hatスタイルのスライドから離れて、手書き風のイラストを多用したところが新鮮だった。
WACOCA: People, Life, Style.