

 Webブラウザから数秒の音声ファイルをアップロードするだけで、その声質に似た1分ぐらいの合成音声を数秒で生成できる
Webブラウザから数秒の音声ファイルをアップロードするだけで、その声質に似た1分ぐらいの合成音声を数秒で生成できる
「他者とのコミュニケーションに対して心理的支障を抱えている人」は、得てして自分の声や発声能力に対してもコンプレックスを持っているものである。思い通りの声色が出せない、どもってしまう、だんだん声が小さくなっていく、言葉の始めに「あっ」とか「えっと」とかつけてしまう、台本通りに読もうと思ってもつっかえるなどなど、程度の差こそあれその理由は千差万別だ。本来は適切なトレーニングを受ければある程度解消はするらしいが、あくまで「ある程度」となる。
そこで今回は自分がトレーニングするのは苦手だが、GPUにトレーニングさせるなら得意な読者に向けて、お手軽に自分の声を生成する「 GPT-SoVITS 」を紹介しよう。
GPT-SoVITSはGPTやSoVITSの仕組みを利用して、テキストから任意の音声を生成するソフトウェアだ。その特徴はなんといっても「ゼロショットTTS」と呼ばれる、数秒の音声データからその声色に合わせた音声データを合成できることだろう。公式サイトでも次のような特徴があげられている。
ゼロショットTTS:5秒の音声サンプルがあればすぐに音声合成を試せる数ショットTTS:1分程度のトレーニングデータからファインチューニングされたモデルを生成し、より実際の声に近い音声合成を実現する言語変換:特定の言語から、日本語・英語・韓国語・広東語・中国語の音声を生成できるWebUI:上記やトレーニング用データを生成するための音声ファイルの分割・テキストラベルを生成するWeb UI
Web UIを備えた、マシンラーニングを用いた音声合成と言えば「 Style-Bert-VITS2 」も有名だ。Style-Bert-VITS2は、声の感情や抑揚を自由に変更できたり、音声合成のみであればCPUだけでも動くなど実用性は高い。GPT-SoVITSの強みは、「自分の声」を生成するための手間が少し少ないことと、別言語の言葉も生成できることと言えるだろう。このあたりは用途に応じて使い分けることになる。
GPT-SoVITS環境の準備
それではさっそくGPT-SoVITSの実行環境を準備することにしよう。GPT-SoVITSの推論自体はGPUがなくても動くが、今回は学習も行なうのでGPUを使う前提で環境を構築する。具体的には次のマシンを使用した。
使用環境マシンMINISFORUM MS-01CPUIntel Core i9-13900HメモリDDR5-5200M 64GiBGPURTX A1000 8GiBOSUbuntu 24.04 LTS Desktop
GPU版のGPT-SoVITSはPython 3.9、PyTorch 2.0.1、CUDA 11もしくはPython 3.10、PyTorch 2.1.2、CUDA 12.3で確認しているとのことなので、Python 3.9環境を用意しなくてはならない。提示されている選択肢は次の2種類だ。
condaコマンドをインストールし、condaで環境を構築するDockerを用いて環境を構築する
Ubuntuであればどちらの手順でも問題はない。あえて比較するとすれば、Dockerのほうが若干構築は簡単だろうか。今回はDockerを使う方法で説明することにする。またNVIDIAのGPUドライバーは事前にインストールされているものとする。このあたりは第56回などを参照して欲しい。
まずは必要なパッケージをインストールしよう。
ここではUbuntuの公式リポジトリにあるDockerパッケージを使っているが、Dockerが提供するパッケージでも問題ない
$ sudo apt install git docker.io docker-compose-v2 curl
$ sudo adduser $USER $USER
dockerグループに所属した状態を反映するには、一度再起動するか「newgrp docker」を実行する必要がある。最近はログアウトだけだと反映されないこともあるので注意しよう。
またDockerコンテナの中からNVIDIAのGPUを使う場合は、NVIDIA Container Toolkitをインストールしておく必要がある。
NVIDIA Container Toolkitのインストール
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg –dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed ‘s#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g’ | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt -U install nvidia-container-toolkit
$ sudo nvidia-ctk runtime configure –runtime=docker
$ sudo systemctl restart docker
これでDocker環境の中から、ホストのNVIDIA GPUが見えるようになった。これはほかのGPUを使うDockerイメージでも必要になる作業なので、環境構築時の手順として覚えておくと良いだろう。
次にGPT-SoVITSをダウンロードする。
GitでGPT-SoVITS本体をダウンロードする
$ git clone https://github.com/RVC-Boss/GPT-SoVITS.git
$ cd GPT-SoVITS/
あとは「docker composeコマンドを実行するだけ」と言いたいところなのだが、実はそれでは動かない。というのもGPT-SoVITSは昨年(2024年)8月ぐらいにv2が出たのだが、docker-compose.yamlから参照しているbreakstring/gpt-sovitsイメージは、このv2対応前になっているからだ。v1としては動くがWeb UIが日本語化されていない。よってまずは最新版のDockerイメージを作ることにしよう。
最新のDockerイメージを作る
$ docker build -t my/gpt-sovits .
これは大きなデータのダウンロードなども行なうため、しばらく時間がかかるので実行したらしばらく放置しておこう。
無事にビルドできたら次にdocker-compose.yamlを次のように書き換える。
git diffを使って差分を表示してみた
$ git diff
diff –git a/docker-compose.yaml b/docker-compose.yaml
index aca8ab9..5ea756e 100644
— a/docker-compose.yaml
+++ b/docker-compose.yaml
@@ -1,8 +1,6 @@
-version: ‘3.8’
–
services:
gpt-sovits:
– image: breakstring/gpt-sovits:latest # please change the image name and tag base your environment. If the tag contains the word ‘elite’, such as “latest-elite”, it indicates that the image does not include the necessary models such as GPT-SoVITS, UVR5, Damo ASR, etc. You will need to download them yourself and map them into the container.
+ image: my/gpt-sovits
container_name: gpt-sovits-container
environment:
– is_half=False
@@ -12,6 +10,7 @@ services:
– ./logs:/workspace/logs
– ./SoVITS_weights:/workspace/SoVITS_weights
– ./reference:/workspace/reference
+ – ./GPT_SoVITS:/workspace/GPT_SoVITS
working_dir: /workspace
ports:
– “9880:9880”
@@ -30,3 +29,4 @@ services:
stdin_open: true
tty: true
restart: unless-stopped
+ command: [“python”, “webui.py”, “ja_JP”]
変更箇所は次の4つである。
versionフィールドはobsoleteなので削除しているが、残していても良いimageフィールドを削除して、作成時に「-t」オプションに指定した名前を記述するカレントディレクトリにある事前学習モデルなどが格納されたGPT_SoVITS以下をコンテナの中からも見えるようにするcommandフィールドを追加してwebui.pyの引数として「ja_JP」を追加する
またGPT_SoVITS以下にv2用の事前学習モデルをダウンロードする。具体的にはHugging FaceにあるGPT-SoVITS用のファイルをダウンロードしよう。
ここではgit-lfsでダウンロードする
$ sudo apt install git-lfs
$ git lfs install
$ cd GPT_SoVITS/pretrained_models/
$ git clone https://huggingface.co/lj1995/GPT-SoVITS
$ mv GPT-SoVITS/* .
それではGPT-SoVITSを立ち上げてみよう。
「-d」オプションを指定することで、バックグラウンドでGPT-SoVITSを立ち上げる
$ docker compose -f docker-compose.yaml up -d
(中略)
✔ Network gpt-sovits_default Created
✔ Container gpt-sovits-container Started
ここで「could not select device driver “nvidia” with capabilities」などと表示される場合は、NVIDIA GPUがコンテナの中から見えない状態となっている。前述のNVIDIA Container Toolkitの設定や、ドライバが正しくインストールされているかをもう一度確認しよう。
うまく立ち上がれば、ログにアクセス用のURLが表示されているはずだ。
ここで「0.0.0.0」はすべてのインターフェイスで待ち受けていることを意味する
$ docker compose logs
WARN[0000] /home/shibata/GPT-SoVITS/docker-compose.yaml: `version` is obsolete
gpt-sovits-container | Running on local URL: http://0.0.0.0:9874
gpt-sovits-container | IMPORTANT: You are using gradio version 3.38.0, however version 4.44.1 is available, please upgrade.
gpt-sovits-container | ——–
つまりローカルマシンからなら「http://localhost:9874」でアクセスすれば良い。また、マシンの外からなら「http://マシンのIPアドレス:9874」でアクセスできることを意味する。
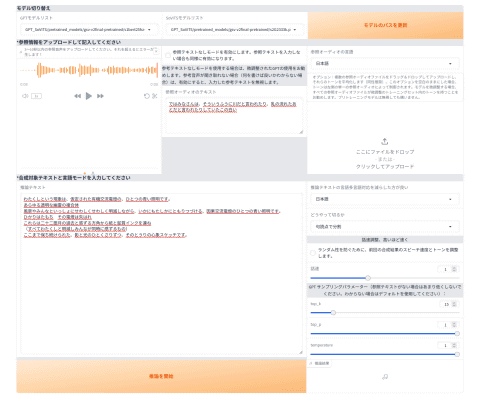
 GPT-SoVITSの起動直後のインターフェイス。正直あまり使いやすいとは言えない
GPT-SoVITSの起動直後のインターフェイス。正直あまり使いやすいとは言えない
無事にページが表示されたら準備が完了だ。
ちなみにGPT-SoVITSはいろいろハマりポイントが存在する。何かうまく動かないと思ったら、ログを見たほうがはやい。しかしながら今回の手順だとバックグラウンドで動いてしまうため、すぐにはログが見られない。そこでどこかの端末で次のコマンドを実行し、常にログを表示しておくと良いだろう。もちろんうまく動くようになるまでは「-d」をつけずに実行するという手もある。
-fオプションを付けることで、出力されるログを常に表示し続ける
$ docker compose logs -f
ゼロショットTTS用の音声データを準備する
では、さっそくゼロショットTTSで音声を出力してみよう。ゼロショットTTSを実行するためにはまず、3秒から10秒の音声データを用意する必要がある。長すぎても短すぎてもダメだ。
適当なPCからマイクを使って録音するのが一番簡単だろう。Ubuntuなら録音アプリを入れるという手もあるが、最初から入っているarecordコマンドもおすすめだ。たとえば次のように実行すると録音デバイスの一覧を表示できる。
arecordはALSA用のツールだ
$ arecord -l
**** ハードウェアデバイス CAPTURE のリスト ****
カード 1: Microphones [Blue Microphones], デバイス 0: USB Audio [USB Audio]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
カード 2: StreamCam [Logitech StreamCam], デバイス 0: USB Audio [USB Audio]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
カード 3: PCH [HDA Intel PCH], デバイス 0: ALC700 Analog [ALC700 Analog]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
録音デバイスは「hw:カード番号,サブデバイス番号」で指定できる。たとえばwavフォーマットで、CD品質のデータとして最大8秒程度保存するなら次のように実行して、マイクに語りかける。
arecordが成功すると録音データが生成される
$ arecord -D hw:1,0 -t wav -f cd -d 8 test.wav
録音中 WAVE ‘test.wav’ : Signed 16 bit Little Endian, レート 44100 Hz, ステレオ
$ file test.wav
test.wav: RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, stereo 44100 Hz
実際に再生してみて、きちんと録音されているか確認しておこう。
ゼロショットTTSを試してみる
音声データができたら、Web UIに戻ろう。
画面上部の「1-GPT-SoVITS-TTS」タブを選択し、さらに中程にある「1C-推論」タブを選択する。そうすると次のように「TTS Interface WebUIを開く」ボタンが表示されるはずだ。
 推論(音声生成)のためのインターフェイス
推論(音声生成)のためのインターフェイス
このボタンを押すと、新しいタブが開いて音声生成画面に遷移する。といいのだが、手元の環境だと何度やっても遷移しなかった。ただ、GPT-SoVITSのログには次のように表示されている。
本来ジャンプするはずのURLが表示される
gpt-sovits-container | Number of parameter: 77.61M
gpt-sovits-container | Running on local URL: http://0.0.0.0:9872
もしURLが表示される前にエラーが出ているようなら、モデルが足りないなどの問題が発生していることになる。手順の実施漏れがないか見直して欲しい。
上記のようにアドレスが表示されているようなら、手動で新しいタブを開いてアドレスバーに「http://localhost:9872」を入力しよう。次のような画面になるはずだ。
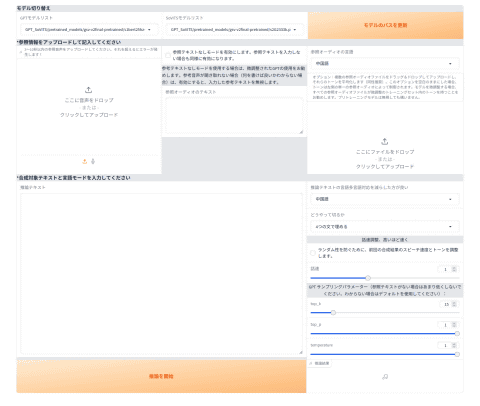 既存のモデルを利用したゼロショットTTSの画面
既存のモデルを利用したゼロショットTTSの画面
使い方はシンプルだ。
左上の「ここに音声をドロップ」から、先ほど作成した音声データをアップロードする真ん中あたりの「参照オーディオのテキスト」にその音声データの発言内容を記述する右上の「参照オーディオの言語」を「日本語」にする左下の「推論テキスト」に生成したい音声の文章を入力する右端の「推論テキストの言語多言語対応云々」を「日本語」に変更するその下の「どうやって切るか」は「句読点で分割」にする「推論を開始」ボタンを押す
無事に推論が完了したら次のように右下に音声データが生成されるため、再生ボタンで確認してみよう。
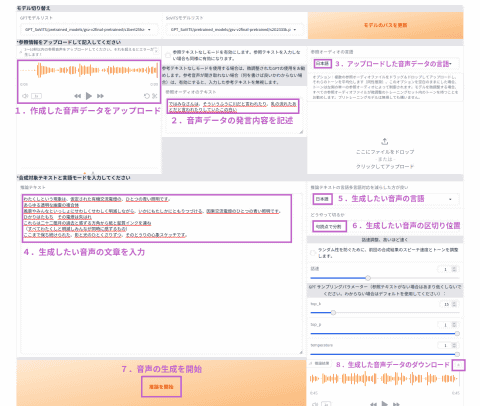 撮影時の都合で画面の下が少し切れてしまっているが、問題はない
撮影時の都合で画面の下が少し切れてしまっているが、問題はない
小さくて分かりにくいかもしれないが音声データの右上にダウンロードボタンもあるため、ダウンロードも可能だ。
・宮沢賢治の「春と修羅」の冒頭を喋らせてみた例
・本連載の第1回の冒頭を喋らせてみた例
・荘子の言葉を喋らせてみた例
・「I Hava a Dream」の冒頭を喋らせてみた例
今回の環境だといずれも10秒未満で生成された。GPUのファンが強く回ることもなかったので、推論(音声生成)だけであればそこまでスペックは必要ないかもしれない。おそらく4GiB以下のVRAMでも問題なく動くはずだ。
なお、英語への変換は必要なデータが足りていなかったため、「Resource averaged_perceptron_tagger_eng not found.」というエラーが表示されてしまった。これを解消するには以下のコマンドを実行する必要がある。
Dockerの中でやっているので一度インスタンスを作り直した場合はもう一度実行しないといけない
$ docker compose exec gpt-sovits bash
# python
Python 3.9.17 (main, Jul 10 2023, 02:46:30)
[GCC 9.4.0] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>> import nltk
>>> nltk.download(‘averaged_perceptron_tagger_eng’)
[nltk_data] Downloading package averaged_perceptron_tagger_eng to
[nltk_data] /root/nltk_data…
[nltk_data] Unzipping taggers/averaged_perceptron_tagger_eng.zip.
True
>>> exit()
# exit
実際に聞いてみると抑揚は小さく、いくつかの箇所のイントネーションもおかしい印象が強い。というか声だけだとほぼ別人な気がする。ちなみにひたすら暗い声に聞こえるのは、純粋にモデル(データじゃなくてテストデータを録音した人という意味のモデル)が悪いのだろう。これについては最初のデータをもっと明るく録れば良かったのだろうか。
自分の声に対するコンプレックスを回避するために音声合成に手を出したのに、生成されたものからさらにコンプレックスを刺激されるという本末転倒な結果になってしまった。
つくよみちゃんコーパスを試してみる
最近は利用の自由度が高い音声データが数多く公開されている。フリー素材キャラクター「つくよみちゃん」が無料公開している「 つくよみちゃんコーパス(CV.夢前黎) 」もそんなデータの1つだ。
このコーパスファイルにはzipでアーカイブされた多数のwavファイルが保存されている。試しにこれの1ファイルをゼロショットTTSに渡してみよう。
zipから1ファイルだけを取り出す
$ unzip -p tyc-corpus1.zip \
‘つくよみちゃんコーパス Vol.1 声優統計コーパス(JVSコーパス準拠)/01 WAV(収録時の音量のまま)/VOICEACTRESS100_001.wav’
> tsukuyomi01.wav
・本連載の第1回の冒頭を喋らせてみた例
・「I Hava a Dream」の冒頭を喋らせてみた例
自分の声との差は歴然である。元のモデルが良いとそれだけ結果も良くなる。そんな正論が時に人を傷つけることがあることを、もっと考えてから試すべきだった。
ファインチューニングで数ショットTTSを試す
GPT-SoVITSには、1分以上の音声データを元によりファインチューニングされたモデルを生成するUIも存在する。これで生成したモデルを使えば、もっと「本人に近い」声質を生成できるというわけだ。
実際に順を追って手順を紹介しよう。先に伝えておくと、次のような手順になる。
1分以上の音声データを生成するそれを数秒ごとのデータに分割する各データのノイズを除去する各データごとに発言内容を記載したラベルデータを作成するトレーニング用のメタデータを作成するデータからSoVITSのトレーニングを行なうデータからGPTのトレーニングを行なう
まずは1分以上の音声データを作成する。実際は上記手順に基づいて無音部分が消されてしまうので、最低でも2~3分のデータを用意しよう。できれば数秒で分割できるように、句読点部分は意識的に無音を作ると良い。先ほどは「-d」オプションで時間を限定したが、今回は限定せずに実行しよう。
あらかじめ台本を用意して読むと良い
$ arecord -D hw:1,0 -t wav -f cd neko.wav
台本を用意して読むようにすれば、発声も安定するし、その台本を後述のラベリング時にも使えるので便利だ。
音声データが用意できれば、Web UIの最初のページ(ポート9874のほう)に移動する。ここから「0-データセット取得ツールの事前処理」タブを選ぶと、手順の2-4をまとめて実行できる。
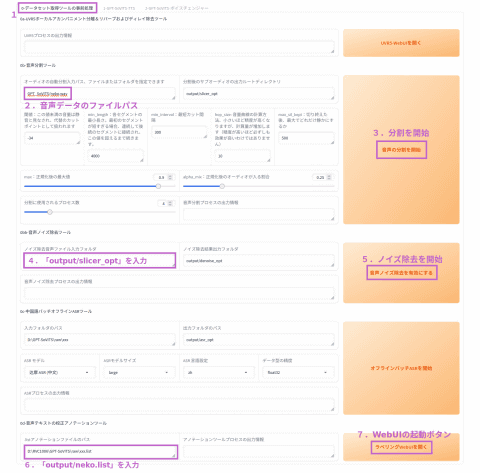 データセット取得ツールの事前処理の画面
データセット取得ツールの事前処理の画面
まず「オーディオの自動分割入力パス」に作成したwavファイルのパスを渡す。今回は「GPT_SoVITS/neko.wav」としたが、コンテナ内部から見える場所であればどこでも良い。
この状態で「音声の分割を開始」を押すと、無音部分を区切りとして複数のファイルに分割してくれる。基本的にパラメータはそのままで良いが、うまく切り出せないようなら録画環境に合わせて調整すると良いだろう。
ファイル名は「元の名前_開始時間_終了時間.wav」だ
$ ls output/slicer_opt
neko.wav_0000056320_0000219840.wav neko.wav_0002625280_0002774400.wav
neko.wav_0000231360_0000419200.wav neko.wav_0002832960_0003072000.wav
neko.wav_0000423040_0000548160.wav neko.wav_0003082240_0003250880.wav
(後略)
ちなみにほかのUIもそうだが、実行中は対象となるパラメータの入力ウィドウにオレンジの枠が表示され、完了すると消える。あと開始すると開始ボタンのラベルは「停止」ボタンに変更し、完了すると元に戻るのが期待動作ではある。ただしGPT-SoVITSの場合、完了後のボタンのラベルは「undefined」となる。ちょっとでもJavaScriptをかじったことがある人なら古傷をえぐられて、頭を抱えると思うが、まごうことなきundefinedだ。
次に「ノイズ除去音声ファイル入力フォルダ」に先ほどの「output/slicer_opt」を指定して「音声ノイズ除去を有効にする」を押すと、ノイズ除去処理を行なってくれる。
ノイズ除去自体はやってもやらなくても良い
$ ls output/denoise_opt
neko.wav_0000056320_0000219840.wav neko.wav_0002625280_0002774400.wav
neko.wav_0000231360_0000419200.wav neko.wav_0002832960_0003072000.wav
neko.wav_0000423040_0000548160.wav neko.wav_0003082240_0003250880.wav
(後略)
「 ラベルデータ 」次のようなフォーマットのテキストデータだ。GPT-SoVITSはこのファイルの自動生成も対応している。
ラベルデータのフォーマット
フォーマット:
vocal_path|speaker_name|language|text
実例:
output/denoise_opt/neko.wav_0000056320_0000219840.wav|neko|ja|吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。
中国語以外の生成については、Faster Whisperを使うことになっているがうまく動作しなかった。どうやら内部的にcuDNNを使おうとするもののライブラリが見つからず「Unable to load any of {libcudnn_ops.so.9.1.0, libcudnn_ops.so.9.1, libcudnn_ops.so.9, libcudnn_ops.so}」というエラーが表示されてしまっているようだ。Dockerでやるなら、ここにコンテナの中にlibcudnnを含むCUDA関連パッケージをインストールすることになるが、少し手間がかかる。
そもそも、ただ生成されるものについては上記のようにはっきりしているため、手で作ってもそこまで大変ではないだろう。とりあえずつぎのようなコマンドで一度に作ってしまう。
ラベルデータの前半部分のみを作る
$ ls -1 output/denoise_opt/ | sed ‘s,\(.*\),output/denoise_opt/\1|neko|ja|text,’ \
| sudo tee output/neko.list
次に「listアノテーションファイルのパス」に先ほど作成した「output/neko.list」を指定して、「ラベリングWebUIを開く」ボタンを押す。そうすると新しいタブが、やはり開かないので、以下のログを確認しよう。
ラベリングWebUIのURL
gpt-sovits-container | Running on local URL: http://0.0.0.0:9871
「http://localhost:9871」にアクセスすると、個々の音声データの内容を聞きながら、文字列データを埋められるUIになってくれる。
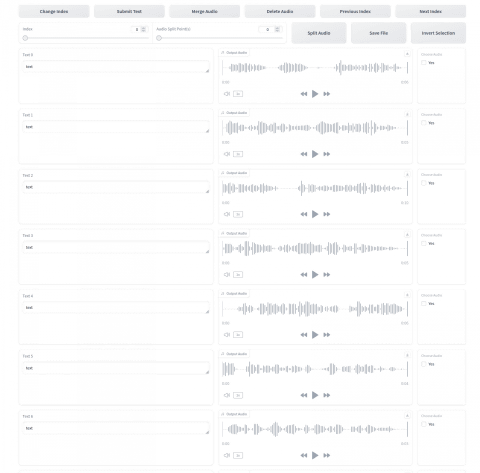 ラベリングWebUIの文字列部分には先ほど設定した「text」が全部入っている
ラベリングWebUIの文字列部分には先ほど設定した「text」が全部入っている
しかしながらこのUIは手元の環境だとものすごく重かった。同様に動きが緩慢なようなら、wavファイルをファイルブラウザから開いて、neko.listに直接文字を入力したほうが楽かもしれない。
ここまででトレーニングデータは完成だ。ちなみにneko.listのうち3秒から10秒の範囲にない音声データがある場合は、除外しておいたほうが良いかもしれない。
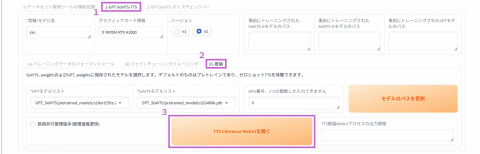
次にデータを元にトレーニングを行なう。まず「1-GPT-SoVITS-TTS」タブを開いて「1A-トレーニングデータのフォーマットツール」を選択する。
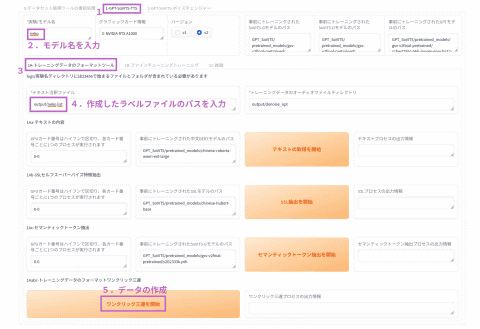 トレーニングデータのフォーマット画面
トレーニングデータのフォーマット画面
実験/モデル名に任意の文字列を入れて、「テキスト注釈ファイル」に先ほど作成したファイルパスを指定する。あとは「ワンクリック三連を開始」を押すと、「logs/モデル名」以下にモデルのメタデータが作成される。
今回のモデル名は「neko」とした
$ ls logs/neko/
2-name2text.txt 3-bert 4-cnhubert 5-wav32k 6-name2semantic.tsv
さらに「1B-ファインチューニングトレーニング」を開く。
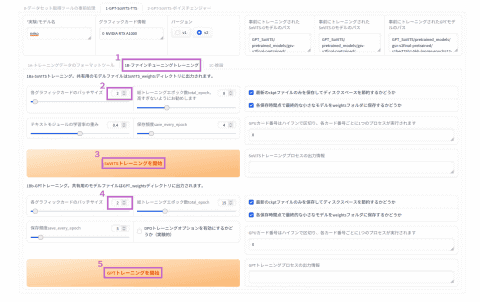 ファインチューニングトレーニング画面
ファインチューニングトレーニング画面
バッチサイズは環境にもよるが、VRAMが8GiB未満なら1、8GiB以上なら2ぐらいで、あとはVRAMに合わせて増やすことになる。それ以外は特に変更する必要はないだろう。この状態で「SoVITSトレーニングを開始」ボタンを押す。そうするとGPUが全力で稼働を始めてトレーニングを開始するはずだ。
トレーニングが完了したら、「logs/モデル名」以下にSoVITSのトレーニング結果が保存される。
先ほどよりファイルが増えた
$ ls logs/neko/
2-name2text.txt config.json
3-bert eval
4-cnhubert events.out.tfevents.1739086781.3ea1c3b46432.2580.0
5-wav32k logs_s2
6-name2semantic.tsv train.log
続いて「GPTトレーニングを開始」したいところだが、このまま実行しても「Index tensor must have the same number of dimensions as self tensor」とのエラーが表示されてしまう。どうやらtorchmetricsパッケージをダウングレードしないといけないようだ。
ここはアドホックな対応ではあるものの、コンテナの中にログインしてダウングレードしてしまおう。
“あまり褒められたやり方ではない。正しくはrequirements.txtあたりを変更してから、Dockerイメージをビルドし直すのが成道だろう。
$ docker compose exec gpt-sovits bash
# pip install torchmetrics==1.5
# exit
これで「GPTトレーニングを開始」を押せば成功するはずだ。あとはトレーニングデータを適切な場所にコピーする。
このあたりもっと良いやり方があるのかもしれない
$ sudo cp logs/neko/logs_s1/ckpt/epoch\=14-step\=180.ckpt GPT_weights_v2/neko-e15.ckpt
$ sudo cp logs/neko/logs_s2/G_233333333333.pth SoVITS_weights_v2/neko_e8_s400.pth
「1-推論」に移動し、「モデルのパスを更新」を押し、「GPTモデルリスト」と「SoVITSモデルリスト」をそれぞれ上記でコピーしたものに変更しておく。
最後に「TTS Interface WebUI」へと戻りたいところだが、もうひと手間必要だ。どうやらPyTorchのバージョンの都合か、作られたモデルを利用しようとすると「Weights only load failed.」というエラーが表示されてしまう。GPT-SoVITSのコードを変更する必要があるらしい。
これもDockerインスタンスの中で無理やり変更する
$ docker compose exec gpt-sovits bash
# sed -i ‘s/\(torch.load.*\))/\1,weights_only=False)/’ GPT_SoVITS/inference_webui.py
# exit
あとはゼロショットTTSと同じ方法で「推論テキスト」に生成したい文字列を入れて「推論を開始」ボタンを押せば良い。ちなみに「数ショットTTS」の場合は、「参照情報」の部分は空で良い。
・本連載の第1回の冒頭を数ショットTTSで喋らせてみた例
事前トレーニングモデルよりもだいぶ自分の声に近くなった気がする。ただ抑揚はさらに小さくなり若干棒読み感が強くなった印象もある。やはりモデルデータの元となった音声データ作成時に、もっと抑揚を付けてはきはきと喋ることが重要そうだ。それができたら最初からこんなことしていないのに。音声については、まずは自己トレーニングをがんばろう。
告知
来週末の2月21日(金)から22日(土)にかけて、オープンソースカンファレンス2025 Tokyo/Springが東京都は世田谷区の「駒澤大学駒沢キャンパス」で開催されます。
Ubuntu Japanese Teamも両日参加し、ブースではUbuntuがインストールされた機材をいくつか展示する予定です。
WACOCA: People, Life, Style.