


AMD「Ryzen Threadripper」シリーズ(以降Ryzenは省略)のZen 5版である「Threadripper 9000」シリーズの流通が始まっている。先行していたプロ向け「Threadripper PRO 9000 WX」よりも同コア数なら“やや”安めの価格設定となっている。
PRO 9000 WXシリーズは8chメモリーと最大144レーンのPCI Express(うち120レーンがGen 5)という装備に加え、ハードウェアベースのセキュリティー機能である「AMD PROテクノロジー」を搭載しているためだ。無印Threadripperはメモリー4ch、PCI Expressが88レーン(うち80レーンがGen 5)と足回りがやや弱く、AMD PROテクノロジーが非搭載となっている。

AMDの資料より引用。Threadripper 9000シリーズはDDR5-6400対応とPCI Express Gen 5のレーン数が増大するなど足回り強化が最大のポイント。だがブーストクロックがコア数に関係なく最大5.4GHzに設定されるなど、より高クロック志向になっている
またThreadripper 9000シリーズの初値は以下の通りとなっている(ほぼ筆者の予想通りであった)。最上位のThreadripper PRO 9980Xのシステムを用意するとなると、CPUだけで90万円、対応マザーとメモリーをセットで買うだけでさらに32万円程度、合計で120万円程度は最低限必要になる。CPUのコア数に投資は惜しまない、という覚悟を決めた人向けの製品といえるだろう。
Threadripper 9980X
90万5000円
Threadripper 9970X
45万2500円
Threadripper 9960X
26万9500円
本稿はThreadripper 9000シリーズレビューの後編となる。前編ではThreadripper 9000シリーズおよびエキシビション的に参加したThreadripper PRO 9995WXの解説、「CINEBENCH 2024」や「Media Encoder 2025」「Handbrake」などを使用した動画エンコードでのパフォーマンスを中心に検証した。
そして本稿では、前編で紹介しきれなかったテストのほかに、グラフィック要素の含まれるCG/ CAD系ベンチマークやゲーム、そしてAI(LLM)での検証を試みる。HEDT/ プロ向けメニーコアCPUの場合、筆者の経験ではCGレンダリングは強力無比だが、シングルスレッド性能が伸びず結果的にグラフィック処理における性能は逆に低くなりやすい。だがZen 5世代のThreadripperではこの経験を覆す結果は出るのだろうか?
検証環境は?
今回の検証環境もThreadripper 9980Xおよび9970X、とその前世代であるThreadripper 7980Xおよび7970Xの比較を中心に検証する。前編に引き続きThreadripper PRO 9995WXもテストに参加させているが、TRX50チップセットを搭載したマザーで検証しているためThreadripper PRO 9995WXのパフォーマンスの全てを評価できているわけではない、というただし書きの部分も前編と共通である。
そして比較用としてRyzen 9 9950Xも加えているが、メモリー搭載量が違いすぎるため、こちらの結果もまた参考程度に捉えていただきたい。
GPUドライバーはStudio 570.00を使用。Resizable BARやSecure Boot、メモリー整合性やカーネルモードハードウェア強制スタック保護、HDRなどは一通り有効化、ディスプレーのリフレッシュレートは144Hzに設定した。また、Threadripper環境のメモリークロックは各CPUの定格最大値に設定している。
検証環境(Threadripper)
CPU
AMD「Threadripper PRO 9995WX」 (96コア/192スレッド、最大5.4GHz)
AMD「Threadripper 9980X」 (64コア/128スレッド、最大5.4GHz)
AMD「Threadripper 9970X」 (32コア/64スレッド、最大5.4GHz)
AMD「Threadripper 7980X」 (64コア/128スレッド、最大5.1GHz)
AMD「Threadripper 7970X」 (32コア/64スレッド、最大5.3GHz)
CPUクーラー
SilverStone「XE360-TR5」
(簡易水冷、360mmラジエーター)
マザーボード
ASUS「Pro WS TRX50-SAGE WiFi」
(AMD TRX50、BIOS build 9942)
メモリー
G.Skill「F5-6400R3239F32GQ4-T5N」
(32GB×4、DDR5-6400/ 5200)
ビデオカード
NVIDIA「GeForce RTX 4090 Founders Edition」
(GeForce RTX 4090、32GB GDDR6X)
ストレージ
Micron「CT2000T700SSD3」
(2TB M.2 SSD、PCIe Gen 5)
電源ユニット
ASRock「TC-1300T」
(1300W、80 PLUS TITANIUM)
OS
Microsoft「Windows 11 Pro」(24H2)
検証環境(Ryzen)
CPU
AMD「Ryzen 7 9800X3D」
(8コア/16スレッド、最大5.2GHz)
CPUクーラー
SilverStone「XE360-TR5」
(簡易水冷、360mmラジエーター)
マザーボード
ASRock「X870E Taichi」
(AMD X870E、BIOS 3.30)
メモリー
Micron「CP2K16G56C46U5」
(16GB×2、DDR5-5600)
ビデオカード
NVIDIA「GeForce RTX 4090 Founders Edition」
(GeForce RTX 4090、32GB GDDR6X)
ストレージ
Micron「CT2000T700SSD3」
(2TB M.2 SSD、PCIe Gen 5)
電源ユニット
ASRock「TC-1300T」
(1300W、80 PLUS TITANIUM)
OS
Microsoft「Windows 11 Pro」(24H2)
コア数が効く処理・効かない処理
後編最初の検証は「SPECworkstation 4.0」を利用する。このベンチマークはその名の通りプロ向けワーステーションで実行し“そうな”処理を通じて性能を数値化しようというものである。通しで実施すると23個ものテストを実行することになるが、中にはGPUやストレージ向けのテストも含まれているため、そうしたものは除外した。今回はCPU性能の比較に使えるテストを抜粋して紹介しよう。

SPECworkstation 4.0のテストはモジュール形式であり、インストール時に自由に取捨選択できる。今回は「CPU」とタグ付けされたテストを実施した
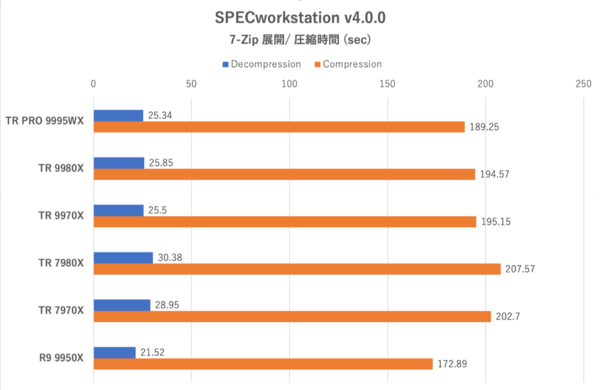
SPECworkstation 4.0:「7-Zip」によるファイル展開および圧縮時間。バーが短いほど優秀
まずは定番アーカイバーのひとつ7-Zipを利用したファイル展開と圧縮時間の比較だ。Threadripperの中ではZen 5世代の9000シリーズの圧縮時間が短く、かつコア数が多いほど処理時間が短縮しているように見えるが、9980Xと9970Xに関しては誤差程度である。一方7000シリーズの場合はコア数の多い7980Xの圧縮時間が長いが、これはブーストクロックが低めに設定されていることが影響していると推察される。
ただ、ここでの総合力トップはRyzen 9 9950Xである。7-ZipテストはSPECworkstationにおいて“Lightly-Threaded”に分類されている。つまり処理の並列度が低いためコア数が多すぎても使いきれず、むしろ少数のよくブーストされるコアで処理した方が速い、ということだ。

SPECworkstation 4.0:「Autodesk Inventor」の処理時間。バーが短いほど優秀
続いてはAutodesk Inventorを利用したテストだ。ファイルを開く・作成する、リビルドやレンダリングするといった作業ごとに要した時間の比較となる。単位はms(ミリ秒)であるため、Threadripper PRO 9995WXならファイルを開く処理で6.35秒、レンダリング処理では11.29秒になる。
Autodesk InventorテストではCPUの負荷が非常に軽い(これもLightly-Threaded分類)ため、コア数の多いThreadripperシリーズは不利だ。Ryzen 9 9950Xはコア数が少なくてもシングルスレッド性能が高く、TDPの枠をCPUコア間で奪い合うこともないため性能は良好だ。
一方ThreadripperシリーズはZen 5世代のThreadripper 9000シリーズが前世代を上回る性能を見せた。コア数の多いThreadripper PRO 9995WXもここではコア数の多さが足かせになっているようだ。

SPECworkstation 4.0:Data Scienceテストの処理時間
上はマルチスレッドに分類されるテストであるData Scienceの結果だ。Pythonを利用したライブラリ(Pandas/ Scikit-learn/ XGBoost)を利用し、AIや機械学習におけるワークフローの処理時間を比較するテストである。
ここへ来てようやくThreadripperが輝くテストが登場した。PandasではRyzen 9 9950Xの処理時間とThreadripperは大差ないが、Scikit-learnでは特にThreadripper 9980Xの処理時間が高速である。Scikit-learnにおけるThreadripper 7980Xと9980Xの処理時間の差は7秒程度だが、Threadripper 7970Xと9970Xでは25秒程度高速になっている。
Threadripper PRO 9995WXはScikit-learnで最速を叩き出しているが、Threadripper 9980Xとの差はごくわずかである。コア数が効かない可能性もあるが、検証環境の関係でメモリー帯域が絞られている結果、Threadripper PRO 9995WXの性能をフルに発揮できていない可能性も大いに考えられる。

SPECworkstation 4.0:「LuxCoreRender」によるレンダリング性能。バーが長いほど優秀
LuxCoreRenderはCGのレンダリングをCPUで実行するテストである。4種類のシーンにおけるレンダリング性能を数値化したものだが、ここではコア数最多であるThreadripper PRO 9995WXがトップ、最少であるRyzen 9 9950Xが最下位である。数値の出方としては前編で紹介した「Blender Benchmark」の傾向によく似ている。Threadripper 9970Xは7970Xを性能において大きく凌駕しているが、コア数の多いThreadripper 7980Xに下剋上を決めるまでには至らない。

SPECworkstation 4.0:PyTorchのコンパイルに要した時間。バーが短いほど優秀
続いてはPyTorchをソースコードよりコンパイルするテストである。このテストでは複数のプロセス(CMake/ninja/ LLVM/ Clang)が使われているため、マルチスレッドというよりはマルチプロセス環境におけるパフォーマンスを比較している(SPECworkstation側による分類もMultiple Processである)。
このテストでもThreadripper 9980Xがトップだが、9970Xとの差は3秒未満と非常に小さく、コア数が決定的な差ではないことが分かる。ただThreadripper 7000シリーズよりも25〜45秒程度高速化していることから、Zen 5アーキテクチャーの採用やメモリークロックの向上、ブーストクロックの引き上げなどが効いていることが示唆される。
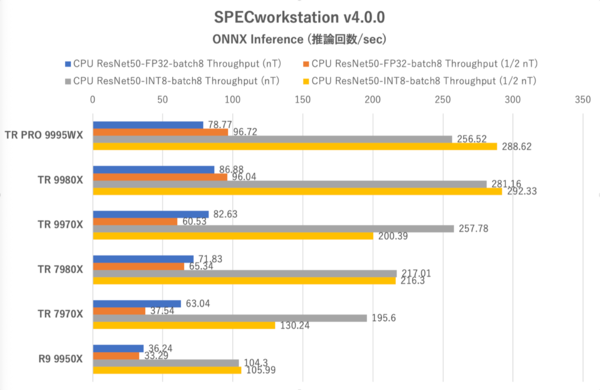
SPECworkstation 4.0:ResNet50における1秒あたりの推論回数。バーが長いほど優秀
ここではAIの推論処理をCPUで行なうONNX Inferenceテストのうち、画像分類で利用されるResNet50の結果、それも1秒あたりの推論回数のみにフォーカスしたものである。演算精度はFP32またはINT8の2通りとし、スレッド数をCPUに搭載されている論理コア数に等しく設定した場合(nTと表記)と、論理コア数の半分に設定した場合(1/2 nT)で計測した。
注目したいのはFP32でのデータの出方だ。全論理コアに処理を振った場合(青いバー)は、コア数と推論回数がほぼリンクする。例外はThreadripper PRO 9995WXだが、192基も論理コアがあってもResNet50の推論では使いきれないということだろう。
だがスレッド数を論理コア数の半分絞った場合(オレンジのバー)、大半のCPUでは推論回数が減っているが、Threadripper 9980XとThreadripper PRO 9995WXの2つに関しては逆に推論回数が増えている点に注目したい。ResNet50の推論処理において32スレッド(Threadripper 9970X)では足りないが、64スレッド程度が好適であることが示唆されている。
しかしThreadripper 7980Xでは1/2 nTにすると推論回数が下がるため、処理に割り当てられたコア数だけが原因ではないようだ。ブーストクロックやメモリー帯域の向上も関係していると考えるのが妥当だろう。
また、INT8を使用した際はどのCPUも推論回数を大きく伸ばしているが、ここでもThreadripper PRO 9995WXとThreadripper 9980Xは1/2 nT設定で推論回数を伸ばしている。Threadripper 9970Xと7970Xは1/2 nT設定だと推論回数が逆に減るのもFP32の結果と共通だが、Threadripper 7980Xは結果に差が出ていない。
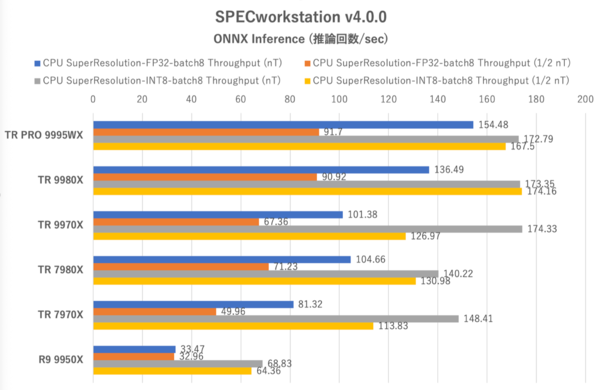
SPECworkstation 4.0:超解像処理における1秒あたりの推論回数。バーが長いほど優秀
同じONNX Inferenceテストでも超解像(Super Resolution)処理における推論回数はどうだろうか? まずFP32では1/2 nTにすると推論回数が大きく下がる(Ryzen 9 9950Xのみが例外だが、これはコア数が圧倒的に足らないためと思われる)。INT8ではThreadripper PRO 9995WXとThreadripper 9980Xにおいて1/2 nT設定時のデメリットを消しているなど、ResNet50の結果とに近い傾向が得られた。
また、このONNX Inferenceテスト全体における傾向を見るとThreadripper 9000シリーズは7000シリーズに対し同コア数でも推論回数を大きく伸ばしている。特にThreadripper 9970Xは7980XにFP32では並び、INT8では大差を付けて勝利している(このあたりはメモリー帯域の向上が効いていそうだ)ことに注目したい。
LLMにおけるパフォーマンスは?
ここでは「LM Studio」を利用したLLMのパフォーマンスを検証してみよう。今回は学習モデルに容量の大きい「Qwq 32B Q8_0」を使用した。学習モデルのサイズは約34GBであり、検証環境で使用したRTX 4090には“大きすぎる”モデルである。Threadripper用検証システムはメインメモリーが128GBあるので、メインメモリーで処理したらどうなるか? という検証になる。
LM StudioでGPUによる処理をしたい場合は「GPU Offload」を最少である0にすればいい。今回はRTX 4090の足りない部分をThreadripperに手伝ってもらうという想定で、GPU Offloadを50%、つまり32にする設定でも検証している。
また、CPUのThread Pool Sizeは最大値に設定してある。64などの値も指定できるが、64にしたところで64スレッド使うような挙動は観測できなかった。
ここでの検証は以下のようなプロンプトを入力し、しばらくシンキングさせるというものである。今回のお題はかなり意地悪で、Qwq 32Bの場合答えを出せずに延々とシンキングを続けてしまう。そこでこのお題を10分間シンキングさせ、トークン出力スピード(OTS:Output Toke Speed)を比較した。
あなたの手には長さ50メートルのロープがあり、高さ100メートルはありそうなビルの高さを測ろうとしています。ただし、あなたの身体(身長は170cm)とロープ(1本しかありません)以外になにも使わず、なるべく正確にビルの高さを計測するにはどうすればよいでしょうか。詳しく解説してください。計算をともなう場合は、その際に使用した数式も提示してください。可能なら図示もしてください。
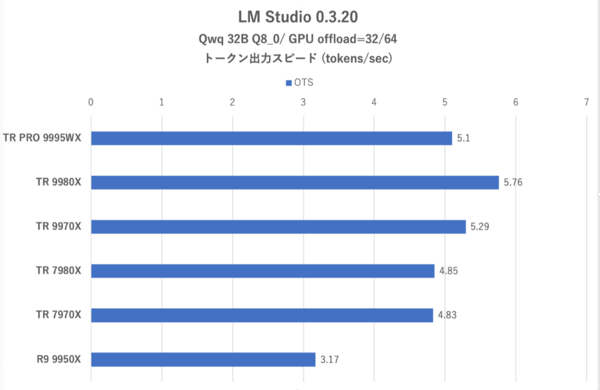
LM Studio:GPU Offloadを32に設定した際のトークン出力スピード

LM Studio:GPU Offloadを0に設定した際のトークン出力スピード。メインメモリーの少ないRyzen 9 9950Xは動かすことすらできないため、テストから除外している
GPU Offloadを0に設定するとトークン出力スピードは下がるが、CPUの速い・遅いの序列はどちらの条件でも大差ない。トップを獲ったのはここでもThreadripper 9980Xであり、Threadripper PRO 9995WXは9980Xにやや劣る。
ただ何回も書くがThreadripper PRO 9995WXのテスト環境は4chメモリーであるため、メモリー帯域が律速になっている可能性は残されている。ただGPU Offloadを0にしてもCPUのコアはわりと遊び気味であるため、単純に処理の並列度が低く、コアの多さを活かせないだけと考えられる。

Threadripper PRO 9995WX+GPU Offloadが0設定の時のCPUの様子。今回テストしたThreadripper PRO 9995WXはコア番号が一番若いコアが優秀(Prefereed Core)であるため、エンコード時は若いコアが使われる傾向が強いのだが、LM Studioでは中盤のコアのみが集中的に使われる挙動が観測された
CG/ CAD系における描画性能
ここからはグラフィック系のパフォーマンス検証となる。まずはThreadripperの想定するユーザーが使いそうなプロ向けアプリにおけるグラフィックパフォーマンスを「SPECviewperf 15」を用いて検証してみよう。
もともと「Maya」「Solidworks」といったアプリにおけるOpenGLの描画パフォーマンス(主にクイックレンダーやプレビューレンダー)を検証するためのベンチマークだが、現行バージョンではDirectX 11やDirectX 12/ Vulkanを利用するアプリも含まれている。テストは画面の解像度を3840×2160ドット、GUIのスケーリングを100%に設定して実施している。

SPECvieperf 15:「3ds Max 2023(3dsmax-08)」「Blender v3.6 LTS(blender-01)」「CATIA V5/ 3DEXPERIENCE CATIA(catia-07)」「Creo 9(creo-04)」、におけるフレームレート(平均)
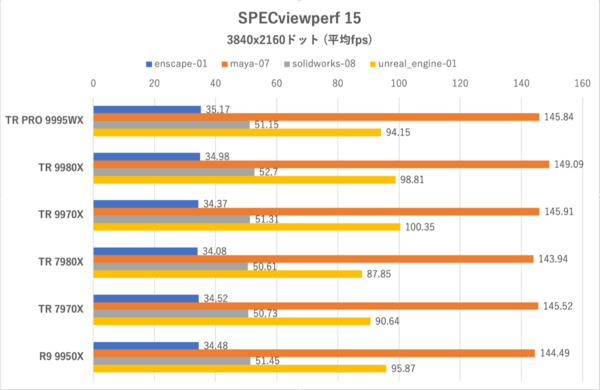
SPECvieperf 15:「Enscape 4.0(enscape-01)」「Maya 2025(maya-07)」、「medical-04」「Solidworks 2024(solidworks-08)」「Unreal Engine v5.4.2(unreal_engine-01)」におけるフレームレート(平均)
フレームレートの出方の傾向は同じではない。同じOpenGLベースのグラフィックでも、blender-01やcatia-07はどのCPUもまったく差がない一方で、creo-04はコア数が少ないCPUでフレームレートが伸びやすいという傾向が見られた。
DirectX 11を使用している3dsmax-08ではThreadripper 9980Xのフレームレートが僅差でトップを勝ち取っているが、DirectX 12を使用しているunreal_engine-01ではThreadripper 9000シリーズの方が7000シリーズよりフレームレートが出るが、同シリーズ内ではコア数の少ないモデル(今回の場合はThreadripper 9970X)の方が伸びるという複雑な傾向を見せている。
enscape-01はVulkanを利用して描画しているが、creo-04などよりも描画負荷の非常に高いテストであるため、GPU(RTX 4090)側が律速になっていると思われる。unreal_engine-01も描画負荷の重いテストを使用しているが、こちらはenscape-01よりも描画負荷が高くないためCPUの影響が出ていると推察される。
ゲームにも強くなったThreadripper
ここからはゲームを利用した検証に入ろう。200万円以上するThreadripper PRO 9995WXでゲームをするというのはナンセンスの極みではあるが、ゲームのような処理において新旧メニーコアCPUはどのような働きを見せるのか、そこに注目していただきたい。
今回はCPUのテストであるため解像度はフルHD(1920×1080)のみ、画質はGPUが律速とならないよう最低設定とした。ただしアップスケーラーやフレーム生成系の技術は使用しない。また、フレームレートの計測は「CapFrameX」を利用し、ディスプレーの書き換えタイミングでフレームレートを計算する(msBetweenDisplayChange基準)のは筆者が手がけた最近のGPU系ベンチマークと共通である。
「Overwatch 2」
ゲーム検証の1番手はOverwatch 2だ。APIはDirectX 11、画質「低」をベースにレンダースケール(RS)100%、さらにフレームレート上限を600fpsに設定。マップ「Eichenwalde」におけるBotマッチを観戦中のフレームレートを計測した。

Overwatch 2:1920×1080ドット時のフレームレート
最もフレームレートが出たのはRyzen 9 9950Xだがそのすぐ後ろにThreadripper 9970Xが続く。Threadripper 7000シリーズは9000シリーズより明確にフレームレートの出方が鈍く、アーキテクチャーやメモリークロック、さらにブーストクロックの差による影響が大きいことがわかる。
3D V-Cacheを搭載したRyzen X3Dシリーズには到底およばないだろうが、Zen 5世代のThreadripper 9000シリーズはゲームにおけるパフォーマンスも向上していることがうかがえる。
「DOOM: The Dark Ages」
DOOM: The Dark Agesでは画質を「低」、アンチエイリアスTAA、パストレーシングはオフに設定した(DOOM: The Dark Agesの場合、パストレーシングはオフにしてもレイトレーシングは使用されるようだ)。ゲーム内ベンチマーク再生中のフレームレートを計測した。ベンチマークシーンは“深淵の森”である。

DOOM: The Dark Ages:1920×1080ドット時のフレームレート
Overwatch 2と同様にThreadripper 7000シリーズは明らかにフレームレートが出にくいことがわかる。ただDOOM: The Dark AgesはCPUの負荷が低く、CPUの格差がOverwatch 2ほど出ていない。強いていえばThreadripper 9970Xがここでも好調(しかもRyzen 9 9950Xを抜いている)だが、誤差レベルの差である。
「F1 25」
F1 25では画質を「超低」、アンチエイリアスを「TAA&FidelityFX」とした。ゲーム内ベンチマーク再生中のフレームレートを計測するが、シーンは“ラスベガス”、天候は「ウエット」を選択している。

F1 25:1920×1080ドット時のフレームレート
Threadripper 7000シリーズに対する9000シリーズの伸びにまず注目したい。7000シリーズは250fpsあたりで頭打ち気味になっているのに対し、9000シリーズは300fps弱まで伸びる。ここでもフレームレートのトップはThreadripper 9970Xであり、コア数が増えるほどフレームレート的には不利になることもわかる。
そしてRyzen 9 9950XはThreadripper 9970Xよりフレームレートが伸びないことを考えると、Ryzen vs Threadripperの対立軸ではコア数というよりメモリークロックの差が強く効いていると考えられる。
「Marvel’s Spider-Man 2」
最後はMarvel’s Spider-Man 2だ。このゲームは画質を下げてもCPUの負荷が非常に高いことが経験上わかっている。ThreadripperのようなCPUが輝く可能性は十分にある。
画質は「非常に低い」設定とし、レイトレーシングはオフ、アンチエイリアスはTAAに設定した。マップ内の一定のコースを移動した際のフレームレートを計測した。

Marvel’s Spider-Man 2:1920×1080ドット時のフレームレート
ここでもThreadripper 9970Xは強いし、Threadripper 7000シリーズは謎の壁に阻まれてしまう。Marvel’s Spider-Man 2程度にコア数を必要とするゲームでも、Threadripper 9970Xよりコア数を増やすと逆にハンデになるようだ。
最後に「ThreadripperとRTX 4090を使って最低画質での検証はナンセンス」と憤慨する人向けに、最高画質設定での検証結果も紹介しよう。DOOM: The Dark AgesとF1 25はパストレーシングを使用しているため非常に重い。先ほどに引き続きアップスケーラーやフレーム生成系の技術は一切使っていないため、GPU側が強烈な律速になり得る設定である。

Overwatch 2:1920×1080ドット時のフレームレート。画質は「エピック」とした

DOOM: The Dark Ages:1920×1080ドット時のフレームレート。画質は「ウルトラナイトメア」、パストレーシング有効としたがDLSS RR(Ray Reconstruction)ではなくNVIDIAのリアルタイムデノイザーを使用している
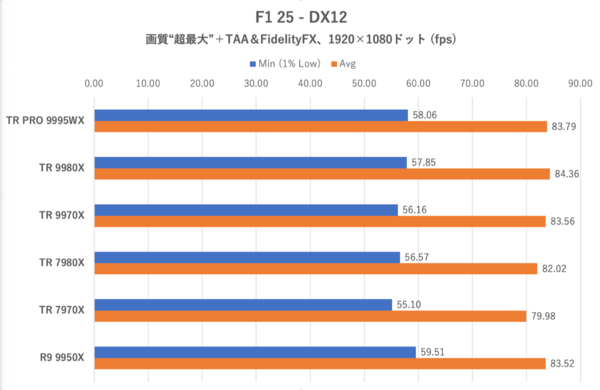
F1 25:1920×1080ドット時のフレームレート。画質は「超最大」とした

Marvel’s Spider-Man 2:1920×1080ドット時のフレームレート。画質は「非常に高い」、レイトレーシング「アルティメット」設定とした。レイトレーシングで反射を追跡するオブジェクト範囲は最大としている
描画負荷の(比較的)軽いOverwatch 2では差が付いたが、パストレーシングが強烈な律速になるDOOM: The Dark AgesやF1 25ではCPUの差がほとんど埋もれてしまった。ただMarvel’s Spider-Man 2の場合、Ryzen 9 9950XとThreadripper 7970Xが同レベルになるあたり、描画負荷を上げることでCPUのコア数不足があらわになったと考えられる。Marvel’s Spider-Man 2でもThreadripper 9970Xは安定して強い点は特筆すべきだろう。
コア間レイテンシーは増大するも、全体の性能は向上
ここで趣向を変え、CPUのコア間レイテンシーはどう変化したかを確認しておこう。ここでは「Core-to-core Latency Tools+(Githubのリポジトリー)」を利用し計測した。計測にあたっては各コアの反復回数を5000、サンプル数を300とした。数値はすべてナノ秒(ns)単位である。

Threadripper 9980Xのコア間レイテンシー。左上がコア0、そこから右ないし下に行くほど、コア番号は大きくなる。ナナメに入っている黒いエリアは同コアなのでスキップされている

Threadripper 7980Xのコア間レイテンシー
CPUコアが8基ずつCCDに格納されている関係上、Threadripperのコア間レイテンシーは同CCD内だとレイテンシーが短く(図では緑)、異なるCCD間だとレイテンシーが長く(黄〜赤色)なる。Zen 4とZen 5のコア間レイテンシーを比較した場合、Zen 5の方がコア間レイテンシーが長くなることはRyzen 9000シリーズのレビューでもわかっており、今回のThreadripperでもまったく同じ傾向が観測されているわけだ。

Threadripper 9 9980Xのコア間レイテンシー(左上部分の拡大)

Threadripper 7980Xのコア間レイテンシー(左上部分の拡大)
こうして拡大してみると、Threadripper 9980Xは7980Xに比べ、コア間レイテンシーが明らかに長くなっている。同CCD内では4〜7ns、異CCD間では20ns以上長くなっている場合もある。このあたりもRyzenとまったく同じである(同じCCDを使っているので当然だが)。
さて、このコア間レイテンシーのチャートでは緑のエリアが4つ、つまりCCDが4つしか見えていない。それはThreadripper 9980Xや7980Xの半分しか計測していないからだ(横は64個しかない)。これはCore-to-core Latency Tools+が使用しているcore_affinityクレートが検出するコア数の最大値が64だからだ。
Core-to-core Latency Tools+では「core_affinity::get_core_ids()」でコア数を取得しているが、Windows環境で実行すると63(コア番号は0から始まる)が上限となる。-cで使用するコア数を指定することもできるが、64より上ではエラーが出るのだ。Threadripper PRO 9995WXを使用してもこの制限は変わらない。
なぜこのようになるかといえば、Windowsの「プロセッサーグループ」の壁があるからだ。1スレッドが使用できるコア数の上限が64基であるためこうなっている。プログラム側で対策しこの壁を乗り越えられる可能性はあるが、Rustのcore_affinityクレートを改修するだけの力量は筆者にはない。
ならばそのような制限のないOSを使えば良い、ということでArch Linux系列の「CachyOS」を利用することにした。使用したバージョンは検証時点における最新版(250713)である。OSの設定はデフォルトのままであり、ここではSecure Bootはオフで運用している。

Threadripper PRO 9995WXのコア間レイテンシー。コア数の設定は自動判定に任せたままだが、192基の論理コアすべてを網羅できている

Threadripper 9980Xのコア間レイテンシー

Threadripper 7980Xのコア間レイテンシー
Linux環境ではCore-to-core Latency Tools+がしっかりと全論理コアに対し網羅的に計測をしてくれるようになった。Threadripper PRO 9995WXのレイテンシーマップの広大さに驚いた人も多いことだろう。
さて先のWindows環境の結果と比較すると、Linux環境におけるレイテンシーの出方はだいぶ異なる。緑のエリアと黄〜赤色のエリアでの数値の大きさは似ている(Linux環境の方が若干小さい)。
だが緑エリアの出方がLinux環境では大きく異なっている。Windows環境では16×16なのに対し、Linux環境では8×8単位になり、さらに対角線上以外の部分にも緑色のエリアが出現している。左上にある緑色のエリアを1ブロックと勘定した場合、次に右ないし下に出現する緑色のエリアまでのブロック数は、そのCPUが搭載しているCCDの数に等しい。
Threadripper PRO 9995WXの場合12ブロックごとに緑色のエリアが出現するし、Threadripper 9980Xや7970Xは8ブロックごとである。おそらくこれは論理コアが物理コアの後にカウントされるためだろう(時間がないので、どういった実装だからこうなるのか、までは調べきれていない)。

Threadripper PRO 9995WXのコア間レイテンシー(左上部分の拡大)

Threadripper 9980Xのコア間レイテンシー(左上部分の拡大)

Threadripper 7980Xのコア間レイテンシー(左上部分の拡大)
これらのレイテンシーマップから得られることがなにかといえば、Threadripper 9000シリーズにおいても、CCD間をまたぐような処理の場合、このコア間レイテンシーが地味に効いてくるということであり、Threadripperに搭載されたCCDの数によりレイテンシーの短いところと長いところがテーブルクロスの柄のようなパターンを作る、ということである。
予想外に“熱くない”CPU
最後に環境をもう一度Windows 11に戻し、CINEBENCH 2024のマルチスレッドテスト実行中におけるCPUの様子(CPUクロック/ Tctl/Tdie/ CPU Package Power)を観察してみよう。ツールは「HWiNFO Pro」を用いた。
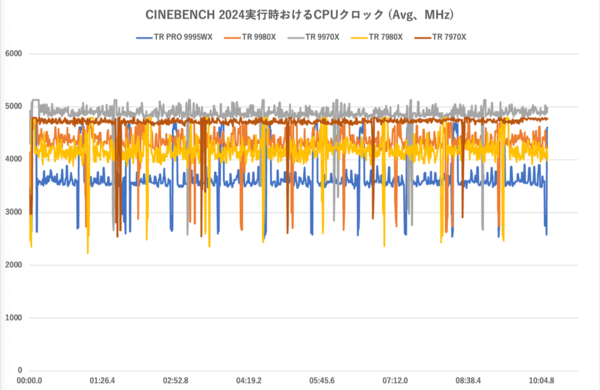
CPUクロック(全コアの平均値)の推移
まずCPUのクロック推移を見ると、最も高クロック動作だったのはThreadripper 9970Xで4.9GHz前後で安定。続いてThreadripper 7970X(4.7GHz前後)、9980X(4.5GHz前後)、最後にThreadripper PRO 9995WX(3.7GHz前後)となった。
コア数最多のThreadripper PRO 9995WXはクロックが大幅に下がってしまうため、Threadripper 9980Xに性能で大差を付けられなかったのも納得がいく。逆に最も高クロック動作となったThreadripper 9970Xがゲームで強かったのもクロックを見れば当然である。
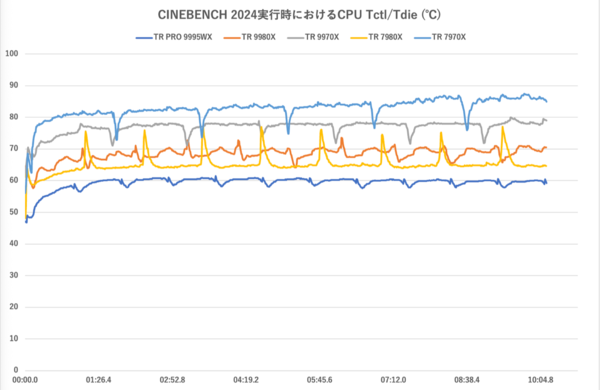
Tctl/ Tdieの推移
Threadripper PRO 9995WXはクロックが低いが、同時にCPU温度も低い。ここではコア単位の温度は記載していないが、今回の環境ではThreadripper PRO 9995WXのコアは50度台中盤〜後半にとどまっており、60度を超えるシーンは合計で10秒程度だった。
一方クロックが最も伸びたThreadripper 9970Xは温度も高いが、それでも80度未満に収まっているし、コア数のもっと多い9980Xは70度近辺を上下している。Threadripper 7000シリーズについてもコア数とCPU温度は相反する関係にあるが、今回のテストでは7970Xの温度が最も高くなった。
Zen 4世代のThreadripper 7000シリーズから、Zen 5世代のThreadripper 9000シリーズへの進化は、CPU温度という点でもしっかり表れている。

CPU Package Powerの推移
最後にCPU Package Powerの推移だが、予想通り350WというTDPの上限に張り付くCPUが続出。Threadripper PRO 9995WXだけが340W前後で頭打ちになっていたが、WRX90マザーで全メモリーコントローラーを使っていたら、350Wに張り付くのではないだろうか?
メニーコアならではの弱点が消えた?
以上でThreadripperレビュー後編は終了である。Threadripper PRO 9995WXの性能は確かにすごいが、これを使い切るには相当に用途が限定される。だがその一方でThreadripper PRO 9970XはCPUのコア数勝負ではやや弱いものの、グラフィック描画が絡む処理では上位の9980Xどころか、Ryzen 9 9950Xを上回る性能を見せた。
これまでHEDT向けCPUはCGレンダリングは超高速だがゲームが絡むとダメなパターンが多かったが、今回のThreadripper 9000シリーズはこういった弱点がキレイに消えている。
無論純粋なゲーム性能を高めたいなら、3D V-Cacheを搭載したRyzen 9 9950X3Dの方が好適であることは言うまでもないが、ゲームの配信や録画においてGPUのエンコーダーは使いたくない(実際にGPUエンコードを見分ける人が配信界隈には居るのだ……)人がCPUパワーを使って高画質で処理したい、という場合にThreadripper 9000シリーズは使えるかもしれない。
いずれにせよ、この価格設定では気楽に買えるものではない。だが新ThreadripperのCPUパワーに心を奪われたなら、検討してみるだけでも損はしないだろう。